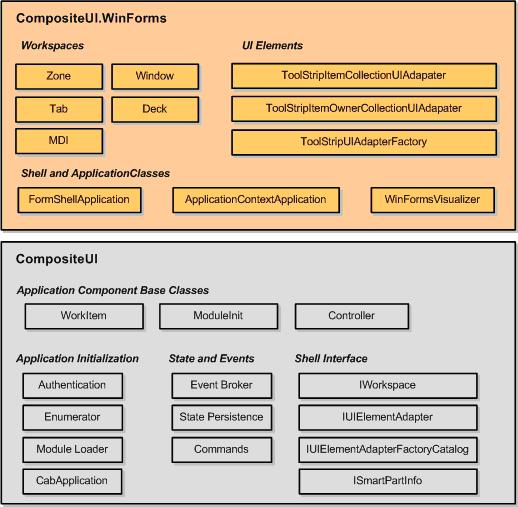
A WorkItem is considered to represent a “use case” in CAB terminology. Ignore this. It is really just a container of other kinds of objects along with some state information.
A CAB application has a tree of WorkItems. The main CabApplication class contains a reference to the root WorkItem, which is referred to by the RootWorkItem property. Given a WorkItem, you can go up one level to its ParentWorkItem, or down to the next level by accessing the workItem.WorkItems collection.
Recall that the main application class is defined like this:
class CABQuoteViewerApplication : FormShellApplication
The first argument in the generic’s argument list is the type of WorkItem that will be the RootWorkItem of our entire application. All other WorkItems will be descendants of this RootWorkItem. A WorkItem has access to any of its descendant’s properties; however, sibling WorkItems cannot access eachother’s properties directly.
A WorkItem also contains various other collections. It has collections of:
- Workspaces
- SmartParts
- Commands
- EventTopics
- Services
- Items (you can stick any object in this collection, including state, views, etc)
You can Activate/Deactivate a WorkItem, Terminate it, and persist it (Save and Load).
There is a virtual function called OnRunStarted() that you can override in order to create views, read data, etc.
WorkItemExtensions
A WorkItemExtension is a way of extending the behavior of a WorkItem without having to change the WorkItem’s code nor resorting to subclassing the WorkItem. It is a class that just receives certain events that happen to the associated WorkItem. These events are:
Initialized
RunStarted
Activated
Deactivated
Terminated
To extend a WorkItem, you need to create a new subclass of WorkItemExtension. Then you need to create an object of that class; this object is associated with an underlying WorkItem. Then you just handle certain events that happen to the WorkItem.
public class QuoteViewWorkItemExtension : WorkItemExtension
{
public QuoteViewWorkItemExtension() {}
protected override OnActivated()
{
PerformanceTimer.StartPerformanceTiming();
}
protected override OnDeactivated()
{
PerformanceTimer.StopPerformanceTiming();
}
}
And, to use this new WorkItemExtension, you would do the following:
QuoteViewWorkItemExtension wix = new QuoteViewWorkItemExtension();
Wix.Initialize(myWorkItem);
©2006 Marc Adler - All Rights Reserved